DNA and Protein Synthesis
Eukaryotic vs prokaryotic DNA
There are structural differences in the DNA found in eukaryotes and prokaryotes:
Eukaryotic DNA is linear, prokaryotic DNA is circular
Eukaryotic DNA is wrapped around histone proteins, prokaryotic DNA is ‘naked’ (not associated with histones)
Eukaryotic DNA is longer than prokaryotic DNA
Prokaryotes can also contain plasmids – small loops of self-replicating DNA.
Genes
A gene is a sequence of DNA bases that code for a protein. The order of bases determines the order of amino acids when the gene is translated, which in turn determines the overall protein structure). The bases are grouped into triplets called codon – each codon codes for a specific amino acid. Before a protein can be made, the gene is first transcribed into messenger RNA (mRNA). The mRNA is transported out of the nucleus to a ribosome for translation into a polypeptide.
Non-coding DNA
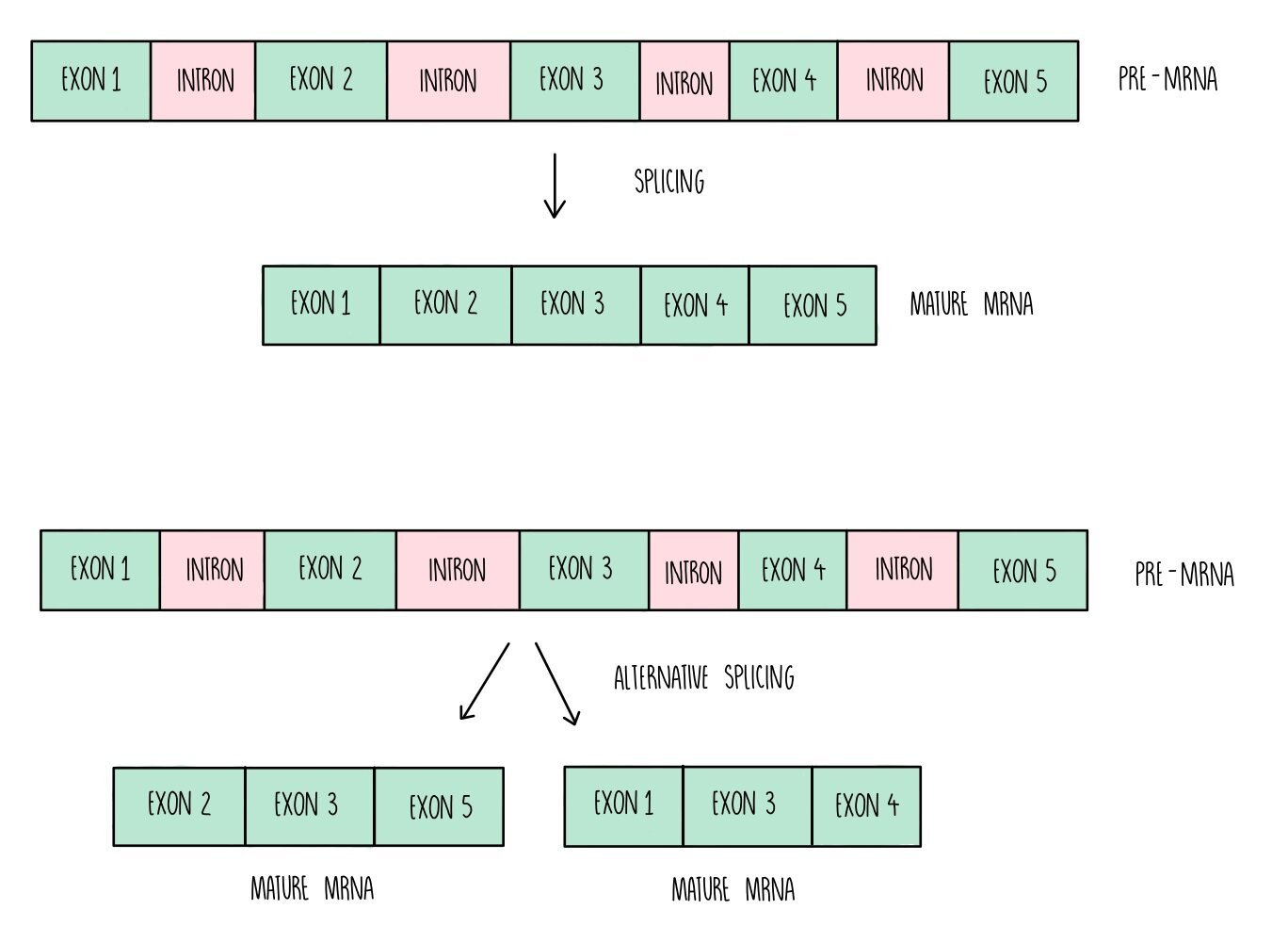
The genome is the complete set of genes present in a cell (or organism). Only a small proportion of the DNA within the genome actually contains the instructions for making proteins. Within a gene, there are sections of DNA known as introns which don’t code for amino acids. These are removed from the mRNA before translation in a process called splicing. This only occurs in eukaryotes – prokaryotic DNA doesn’t contain introns.

Chromosomes and alleles
Human body cells contain 46 chromosomes which come in 23 pairs. One of each pair was inherited from either parent and are referred to as homologous chromosomes.
Homologous chromosomes contain the same genes at the same loci (position) but may contain different forms of the gene (alleles). Two alleles of the same gene will have largely the same DNA sequences, with small base changes resulting in slightly different versions of the same protein.
Types of RNA
Messenger RNA (mRNA)
Produces during transcription – RNA polymerase uses DNA as a template to provide mRNA strand
Carries the genetic code from the nucleus to the cytoplasm – provides the instructions for making a protein on the ribosome in translation
Made up of triplets of bases called codons
Transfer RNA (tRNA)
Carries amino acids to the ribosome during translation
Contains an amino acid binding site at one end and an anticodon at the opposite end
Anticodons bind to complementary codons on mRNA to convert the mRNA sequence into a protein’s primary sequence
Protein synthesis
DNA is too large to leave the nucleus (and too precious to be damaged), so it is first converted into messenger RNA in transcription, which moves into the cytoplasm and binds to a ribosome. Here, it is used to synthesise a protein in the process of translation.
Transcription
For a gene to produce a protein, the DNA within the gene must first be copied into RNA in a process called transcription. During transcription, RNA polymerase binds to the beginning of a gene in an area known as the promoter region. The promoter region is a regulatory region which does not code for amino acids but facilitates the process of transcription by helping RNA polymerase bind to the gene. RNA polymerase separates the DNA strands, producing a single DNA template for transcription. As RNA polymerase moves along one of the DNA strands (the template strand), it adds complementary nucleotides and connects them through the formation of phosphodiester bonds. The other strand is referred to as the coding strand and will have an identical sequence to the newly synthesised RNA, except for the presence of thymine instead of uracil. Eventually RNA polymerase will reach a codon which does not code for an amino acid but tells the enzyme to stop transcribing (these are called stop codons). A molecule of messenger RNA (mRNA) has been formed which will leave the nucleus and enter the cytoplasm.
Translation
Once in the cytoplasm, the messenger RNA finds its way to structures called ribosomes.
The ribosome attaches itself to the RNA and slides along it (this is known as translocation). The ribosome ‘reads’ the mRNA in a series of three bases (such as AUG, CCA, GCU) called codons. Each codon corresponds to a particular amino acid.
As the ribosome reads the codons, a transfer RNA (tRNA) molecule which has a complementary anticodon carries an amino acid to the ribosome. Once the ribosome has read through the length of the mRNA, a series of different amino acids will have been dropped off by several tRNA molecules.
The ribosome catalyses peptide bond formation (condensation reaction) between the amino acids to form a polypeptide.
tRNA molecules have an usual clover-shaped structure, formed by a single RNA strand folded over on itself through hydrogen bonding. At one end of the molecule, there is an amino-acid binding site and at the other there is an anticodon, which contains a complementary base sequence to the mRNA codon.
The Nature of the Genetic Code
The genetic code can be described in a number of ways - it is a triplet code, non-overlapping, degenerate and universal.
Triplet code: three nucleotide bases make up a codon, which code for a particular amino acid.
Non-overlapping code: the codons do not overlap. Once the ribosome has ‘read’ one codon and the appropriate amino acid has been recruited, the ribosome moves onto a new codon.
Degenerate code: different codons can code for the same amino acid. For example, the codons CUU and CUC both code for the amino acid leucine. This means that some mutations will have no effect on the organism since the same protein will still be produced.
Universal code: all organisms use the same genetic code. Bacteria, bonobos and bananas all contain DNA made up of the four nitrogenous bases that are found in humans.