Inheritance
Semi-conservative DNA replication
During cell division, cells need to make a complete copy of their genetic information. When DNA is replicated, the new DNA molecule is made up of one strand of the original DNA whereas the other strand is made of freshly made DNA. Since half of the DNA is preserved from the previous round of DNA replication, we describe the process as semi-conservative. It takes place in the following stages:
DNA helicase unwinds the double helix, breaking the hydrogen bonds between complementary base pairs to separate the strands. One of the strands will act as a template for synthesis of the other strand.
Complementary nucleotides will attach to the template strand by hydrogen bonding.
DNA polymerase catalyses the formation of phosphodiester bonds between nucleotides, forming a complementary strand alongside the template parent strand.
Two daughter DNA molecules are formed, each containing half of the original DNA molecule.
It is important that DNA polymerase accurately copies the template strand to avoid placing the wrong DNA nucleotide in the incorrect position. To avoid this, DNA polymerase ‘proofreads’ the complementary strand as it moves along the DNA. If it detects a mismatch, it can ‘snip out’ the wrong nucleotide and replace it with the right one. DNA polymerase has an accuracy rate of about 99%, which means that mistakes do occur every once in a while. A mistake results in a change to the DNA base sequence, which is known as a mutation. DNA mutations can have detrimental effects to the organism, since an altered base sequence can change the sequence of amino acids in a protein, causing it to fold differently and possibly lose its function.
Meselson and Stahl’s experiment
The evidence that DNA replication is semi-conservative comes from a pretty clever experiment carried out by Matthew Meselson and Franklin Stahl. Before this, scientists were unsure whether DNA replication was conservative or semi-conservative. If DNA replicated conservatively, the original DNA strands would remain intact and the newly synthesised DNA would consist of two freshly-made strands.
To figure this out they used a heavy isotope of nitrogen (N-15) which has an extra neutron compared to the normal, lighter form of nitrogen (N-14). They grew bacteria in the presence of the heavy nitrogen and any new DNA that the bacteria made would incorporate this isotope and so would weigh heavier. If DNA replicates conservatively, Meselson and Stahl knew that they’d see some DNA made of just heavy nitrogen with the rest made of only light nitrogen, but if it replicated semi-conservatively it would be a mixture of the two isotopes. Here’s how they carried out the experiment in more detail:
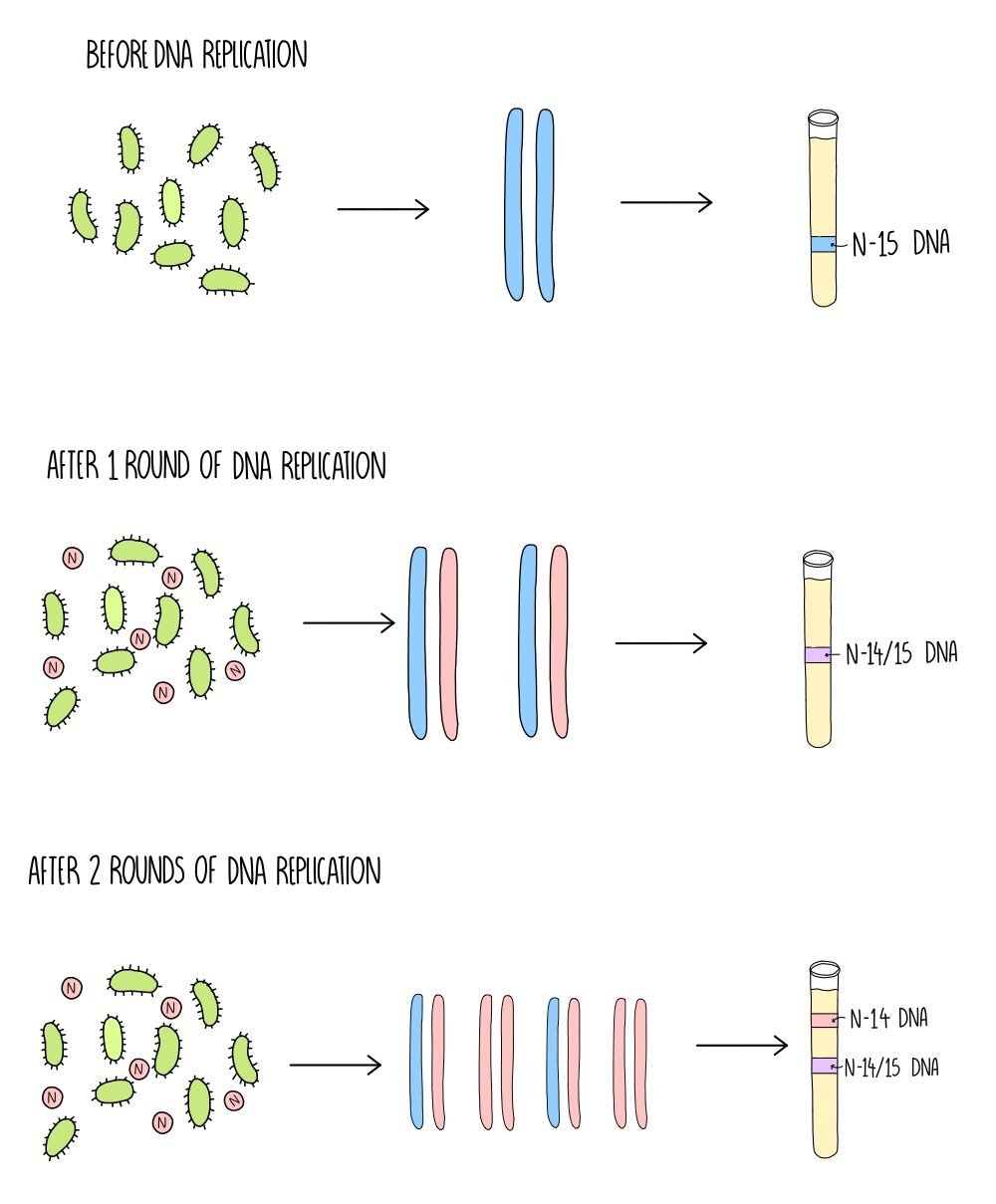
Two populations of bacteria were grown - one in a solution containing heavy nitrogen and the other in a solution containing light nitrogen. As the bacteria grow and reproduce, they incorporate the nitrogen into their DNA.
DNA was extracted from the bacteria and centrifuged to separate the DNA according to its weight. The DNA from the bacteria grown in N-15 separated at a higher density (a band lower down the test tube) compared to the DNA from the bacteria grown in N-14.
The scientists then took the bacteria that had been growing in N-15 (which now just contains heavy DNA) and grew them in the light isotope N-14. Again, they extracted their DNA and separated it using centrifugation.
After the first round of DNA replication, they saw just one band of DNA which was an intermediate weight between 14-N and 15-N. This indicates that the DNA was made up of both types of nitrogen isotopes (i.e. one old strand and one newly synthesised strand).
After the second round of DNA replication, there was now 2 bands of DNA. One band has an intermediate weight but further newly synthesised DNA is now only being made using the lighter isotope. This proved that DNA is replicated semi-conservatively.
If DNA replication is conservative, Meselson and Stahl would have seen two bands of DNA (one heavy and one light) after both the first and second rounds of replication.
Mutations

A mutation is a change to the base sequence of DNA occurring when the cell makes errors during DNA replication. Since the order of bases within a gene determine the amino acid sequence (or primary structure) of a protein, a mutation can result in an altered primary structure. Primary structure then determines later stages of folding, so a mutation can result in a change to the overall 3D structure (tertiary structure) of a protein. This could result in the protein losing its function.
Types of mutation:
Substitution - one base is replaced for another e.g. TGCCTA becomes TGACTA. It results either in a change to a single amino acid, or the amino acid might stay the same because more than one codon can code for the same amino acid (the genetic code is degenerate).
Insertion - one or more bases is added e.g. TGCCTA becomes TGCCCTA. This type of mutation will change the codon (and perhaps the amino acid) and all following codons (this is called a frameshift).
Deletion - one or more bases is removed e.g. TGCCTA becomes TGCTA. Deletion mutations will change the codon at the point of mutation and all following codons, resulting in a frameshift.
Inversion - a sequence of bases is reversed e.g. TGCCTA becomes TGCATC. It will result in a change to a single amino acid.
Some mutations can have a neutral effect on a protein’s function. This could be because:
The mutation changes a base in a triplet but the amino acid that the triplet codes for doesn’t change. This happens because some amino acids are coded for by more than one triplet (the genetic code is degenerate).
The mutation produces a triplet that codes for a different amino acid but the amino acid is chemically similar to the original so it functions like the original amino acid.
The mutated triplet codes for an amino acid not involved with the protein’s function e.g. one that is located far away from an enzyme’s active site, so the protein works as it normally does.
However, some mutations will have an effect and it could be beneficial or harmful to the organism. An example of a beneficial mutation is antibiotic resistance in bacteria (from the bacteria’s perspective). The mutation would allow it to survive in the presence of the antibiotic whereas it would have previously been killed. Other mutations will have harmful effects, such as the mutations which cause cystic fibrosis or cancer.
Genetic diagrams

Monohybrid inheritance is the inheritance of characteristics controlled by a single gene. We can predict the characteristic in the offspring for this type of inheritance using Punnett squares. The parent gametes are written on the side, with the genotypes of possible offspring in the centre.
If the dominant P allele produces purple flowers and the recessive p allele produces white flowers, then we can see that breeding two heterozygous individuals will produce offspring with a 3:1 ratio of purple flowers to white flowers. This 3:1 ratio between the dominant phenotype and the recessive phenotype will always be seen in the offspring of two heterozygotes.
Chi Squared Test
The chi squared test is a statistical test that is used to see if the results gathered during an experiment (the observed results) are what we expected to find (the expected results). We first have to state the null hypothesis - the null hypothesis is always that there is no significant difference between the observed and expected results. The chi squared test will allow us to either accept or reject the null hypothesis.
Look at the example described below to see how you would do this:
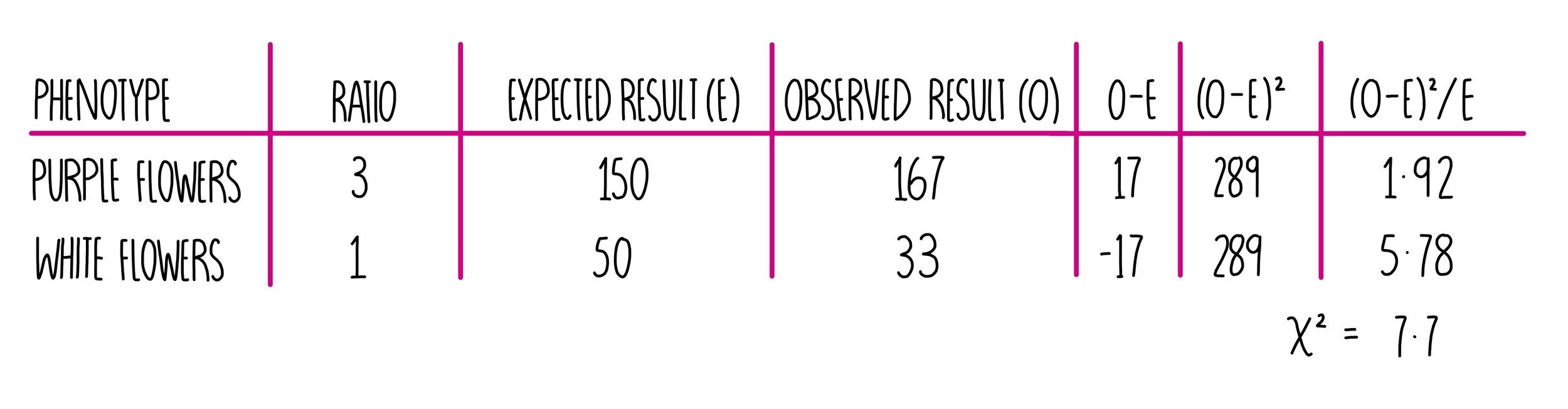
Let’s say you’re carrying out an experiment to determine the genotypes of two organisms for a particular trait. A gene which determines flower colour is controlled by 2 alleles - the dominant allele (P) gives rise to purple flowers and the recessive allele (p) produces white flowers. If two heterozygous purple flowers are crossed, we would expect to see a 3:1 ratio of purple flowers to white flowers in the offspring - these are our expected results.
Now we’ll cross-breed the two plants and determine the number of offspring showing each phenotype. An example is shown in the table below:

Then we use these results to calculate a value for chi squared. We do this by calculating the difference between the observed and expected result (O - E). We then square that number (O - E2) and divide that value by the expected result ((O - E2)/E). The values obtained for both phenotype need to be added together to get our chi squared value.
This can be summarised using the formula below. You don’t need to memorise this formula - you’ll be given it in the exam.
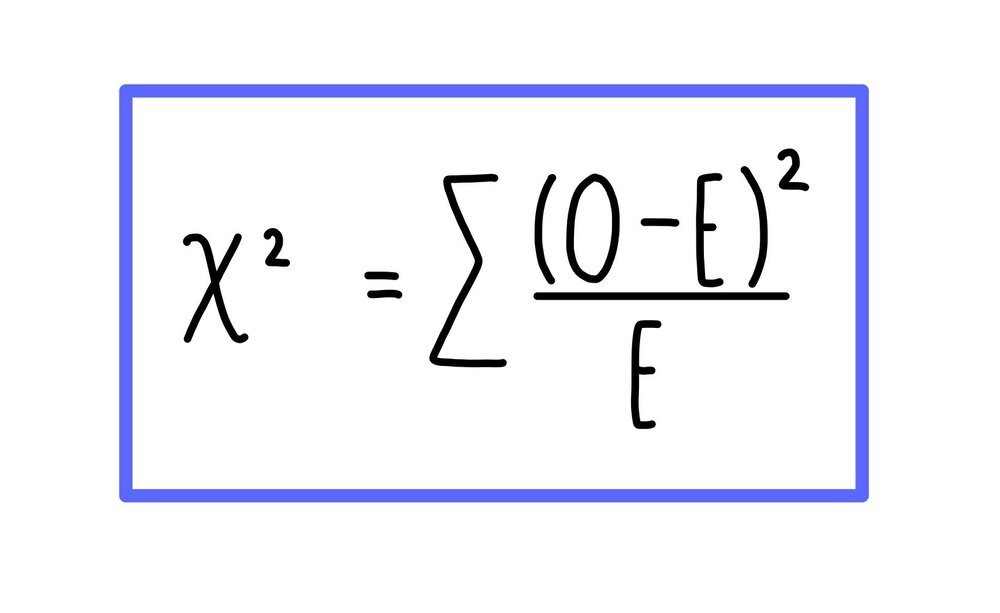
The last thing you need to do is to compare your chi squared value to the critical value. The critical value is the value of chi squared that corresponds to a 0.05 (5%) level of probability that the difference between our observed and expected results is due to chance. If your chi squared value is larger than or equal to the critical value then there is a significant difference between the observed and expected results. This means that something other than chance is causing the difference in the results and the null hypothesis can be rejected. However, if your chi squared value is smaller than the critical value that means there is no significant difference between the observed and expected results. This means any difference between the observed and expected results is the variation you’d expect due to chance and the null hypothesis can be accepted. In this case, this means that our theory that petal colour follows a monohybrid pattern of inheritance is supported.
You may have to work out the critical value for yourself from a table. The table will give you different critical values for different probability levels at different degrees of freedom. The degrees of freedom is equal to the number of groups in the experiment (in this case, the number of different phenotypes) minus one. We had two different phenotypes (purple and white) so our degrees of freedom = 1.

In our experiment, we obtained a chi squared value of 7.7. The critical value at 5% probability (0.05) and 1 degree of freedom is 3.8. Our chi squared value is larger than the critical value which means there is a significant difference between the observed and expected results. The difference is due to something other than chance so we need to reject the null hypothesis. Our results show that the plants we were breeding were not heterozygous or that petal colour in these plants does not follow a simple monohybrid pattern of inheritance.
Cystic Fibrosis
Cystic Fibrosis is a genetic disorder that results from inheriting two recessive alleles. It is caused by a mutation in the cystic fibrosis transmembrane conductance regulator (CFTR) protein which plays a role in transporting chloride ions out of the epithelial cells lining the trachea. In healthy people, CFTR plays an important role in making mucus thin and watery, since the transport of chloride ions decreases the water potential of the mucus lining the trachea, stimulating the movement of water by osmosis. Mutations in the CFTR protein mean that water doesn’t move into the trachea, making the mucus thick and sticky. This thick mucus can clog up tubes in our respiratory, digestive and reproductive systems.

Respiratory system - in healthy people, mucus traps bacteria which are moved into the stomach by the sweeping motion of cilia lining the trachea, where the bacteria-filled mucus will be destroyed by the stomach acid. In people with cystic fibrosis, the cilia cannot move the thick, sticky mucus. It builds up and blocks passages of the airways, reducing the surface area available for gas exchange and making it more difficult to breath. The bacteria inside the mucus can reproduce, leading to lung infections. People with cystic fibrosis can be given antibiotics to kill the bacteria inside the mucus lining their airways. They can also have physiotherapy to help to dislodge the mucus and facilitate gas exchange.
Digestive system - in people with cystic fibrosis, mucus can also build up and cause blockages in the tube which connects the pancreas to the small intestine. This prevents digestive enzymes being secreted into the small intestine, making food digestion less efficient. The presence of thick, abnormal mucus can stimulate the growth of cysts in the pancreas, which also inhibits production of digestive enzymes.
Reproductive system - abnormally thick mucus in men can cause blockages in the tubes which connect the testicles to the penis, preventing the passage of sperm. In women, thick mucus in the cervix can prevent sperm from reaching and fertilising the egg, resulting in reduced fertility.
Genetic Screening
Genetic screening can be used to check whether an individual is a carrier of a recessive allele which causes disease (such as the cystic fibrosis allele), or to check unborn foetuses for genetic abnormalities.
Checking whether an individual is a carrier
If an inherited recessive disorder, such as cystic fibrosis, runs in your family as well as your partners’, you may want to have your DNA checked to determine whether you are both carriers of the cystic fibrosis gene (which means there would be a 25% chance of having a child with cystic fibrosis). If both individuals find out that they carry the disease allele, they may want to undergo prenatal testing to make an informed decision about whether or not to have the child.
There are ethical and social issues with DNA testing:
The results are not 100% accurate - a false positive means unnecessary stress and may lead to a couple choosing not to raise children whereas a false negative may mean that the mother gives birth to a child with cystic fibrosis without being emotionally or financially prepared.
The DNA test may discover other DNA abnormalities, such as a mutation in a gene which leads to breast cancer, which can cause further stress.
Life insurance companies or employers may use the results to discriminate against people with certain genetic disorders.
Prenatal testing
Prenatal testing involves testing the DNA of an unborn fetus while it is still growing in the mother’s womb. An expectant mother may choose to have prenatal testing if she thinks that the baby is at risk of a particular genetic disorder. There are two types: amniocentesis and chorionic villus sampling (CVS). If the tests indicate a positive result, the couple may either choose to undergo an abortion or to keep the child (in which case they have time to prepare themselves mentally and financially). There are ethical issues associated with this - many people feel it is unethical to abort a fetus due to a genetic disorder. Also, both methods involve a risk of miscarriage, so there is a small chance of the baby dying (regardless of whether is has a genetic abnormality).
Amniocentesis
Involves testing fetal DNA by taking a sample of amniotic fluid.
This is done by inserting a long, fine needle through the abdomen.
It is carried out during weeks 15-20 of pregnancy and there is a 1% chance of miscarriage as a result of the procedure.
Results are not available until 2-3 weeks after the sample has been taken.
Chorionic villus sampling
Involves taking a sample of the placenta using a needle which is inserted either through the abdomen (transabdominal) or through the vagina (transvaginal).
It is carried out during weeks 11-14 of pregnancy and there is a 1-2% risk of miscarriage.
Results can be available just a few days after the procedure is carried out.
Since CVS can be carried out at an earlier stage in the pregnancy, and the results are available sooner, this means that if the couple decide to abort the child then the abortion will be less physically (and emotionally) traumatic since the fetus is less developed. However, CVS results in a slightly higher increase in miscarriage. Couples will have conversations with a medical professional about the pros and cons of each of these methods before making an informed decision about which type of genetic test to have.