Nucleotides and Nucleic Acids
Just like carbohydrates, proteins and lipids, nucleic acids are polymers made up of lots of smaller units joined together in long chains. These nucleotides have one of four bases - A, T, G or C - which eventually produce everything that makes a human being, along with the components of every other living thing on the planet. How does it happen? Through the mystifying processes of transcription and translation...
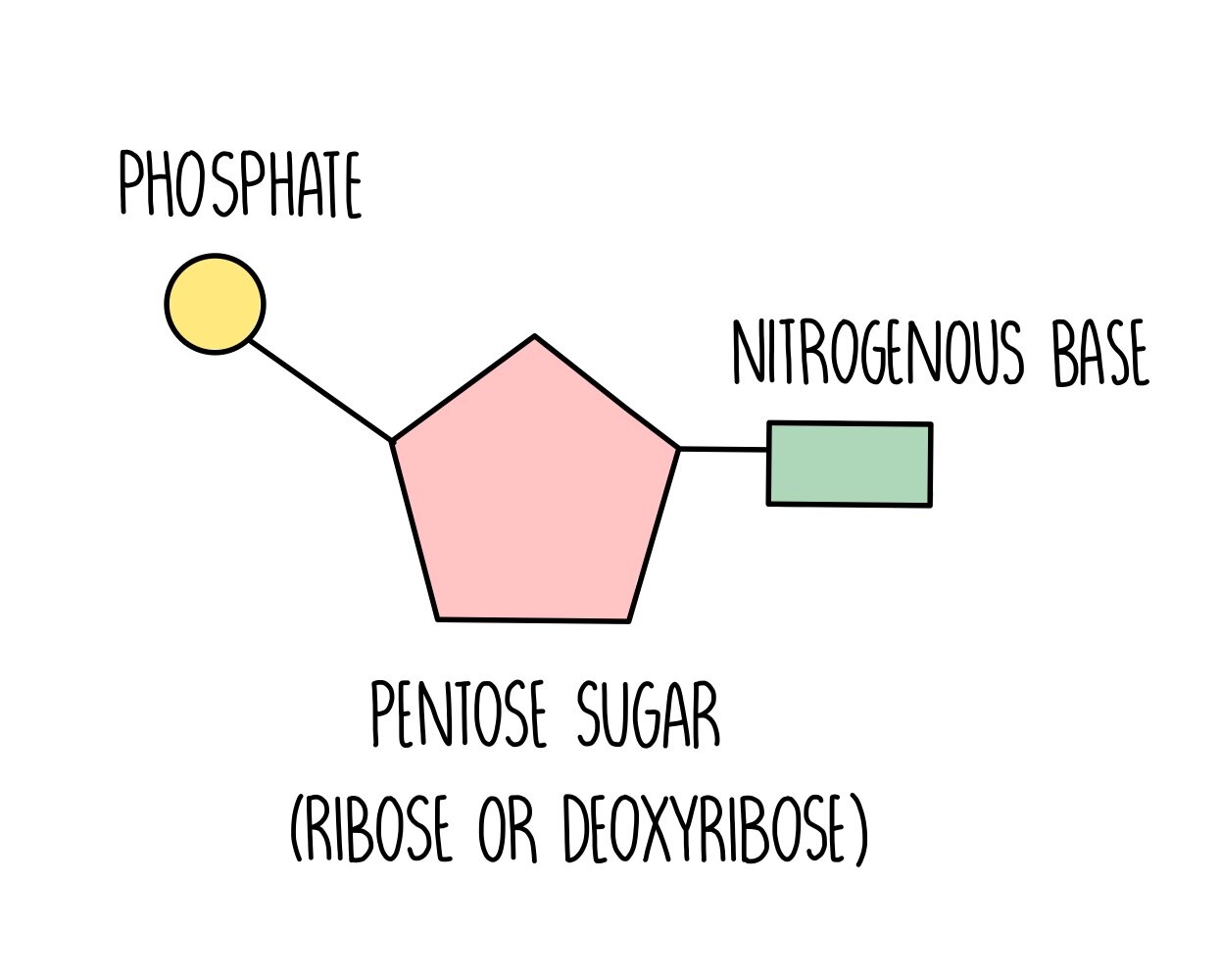
Nucleotide Structure
Nucleic acids are long chains (polymers) of lots of nucleotide monomers joined together by phosphodiester bonds. Each nucleotide is made up of three components: a pentose sugar (either deoxyribose or ribose), a nitrogenous base (guanine, cytosine, adenine, thymine or uracil) and a phosphate group. DNA consists of two nucleic acid strands bonded together by complementary base pairing, the strands twisted around each other to form a double helix. The two strands have the same sequence running in opposite directions so we say they are anti-parallel. The bonding between bases is predictable, since guanine always pairs with cytosine with three hydrogen bonds holding them together. Adenine always bonds with thymine (in DNA) or uracil (in RNA) with two hydrogen bonds between them. Adenine and guanine are purines, which means they have a large double ring structure. Cytosine and thymine are pyrimidines, which are smaller as they are composed of a single ring. Notice that a purine always base pairs with a pyrimidine - this happens because it’s the only way DNA can keep a regular shape and not become too bulky or narrow.

There are some important differences between a molecule of DNA and RNA:
They contain different sugars - the pentose sugar in DNA is deoxyribose and in RNA is ribose. The difference is that deoxyribose has one less oxygen atom.
RNA contains uracil instead of thymine
DNA is double-stranded whereas RNA is single-stranded
DNA has hydrogen bonds between the two complementary strands
During DNA and RNA synthesis, nucleotides are connected through the formation of phosphodiester bonds (a type of covalent bond) between the phosphate group on one nucleotide and the pentose sugar of the next nucleotide. It is a condensation reaction which means that water is formed during the reaction and it is catalysed by an enzyme called DNA polymerase or RNA polymerase depending on whether a DNA or RNA strand is being synthesised. Breaking phosphodiester bonds requires the addition of a water molecule, so it is a hydrolysis reaction.
Semi-conservative DNA replication
During cell division, cells need to make a complete copy of their genetic information. When DNA is replicated, the new DNA molecule is made up of one strand of the original DNA whereas the other strand is made of freshly made DNA. Since half of the DNA is preserved from the previous round of DNA replication, we describe the process as semi-conservative. It takes place in the following stages:
DNA helicase unwinds the double helix, breaking the hydrogen bonds between complementary base pairs to separate the strands.
One of the strands will act as a template for synthesis of the other strand. Complementary nucleotides will attach to the template strand by hydrogen bonding.
DNA polymerase catalyses the formation of phosphodiester bonds between nucleotides, forming a complementary strand alongside the template parent strand.
Two daughter DNA molecules are formed, each containing half of the original DNA molecule.
It is important that DNA polymerase accurately copies the template strand to avoid placing the wrong DNA nucleotide in the incorrect position. To avoid this, DNA polymerase ‘proofreads’ the complementary strand as it moves along the DNA. If it detects a mismatch, it can ‘snip out’ the wrong nucleotide and replace it with the right one. DNA polymerase has an accuracy rate of about 99%, which means that mistakes do occur every once in a while. A mistake results in a change to the DNA base sequence, which is known as a mutation. DNA mutations can have detrimental effects to the organism, since an altered base sequence can change the sequence of amino acids in a protein, causing it to fold differently and possibly lose its function.
Transcription & Translation
For a gene to produce a protein, the DNA within the gene must first be copied into RNA in a process called transcription. This is important because DNA is too big and wrapped snuggly around chromosomes to leave the nucleus. Just like photocopying a single useful page out of a chunky library book, the cell makes an RNA copy of all the important information contained in the gene.
During transcription, RNA polymerase binds to the beginning of a gene in an area known as the promoter region. The promoter region is a regulatory region which does not code for amino acids but facilitates the process of transcription by helping RNA polymerase bind to the gene. RNA polymerase separates the DNA strands, producing a single DNA template for transcription. As RNA polymerase moves along one of the DNA strands (the template strand), it adds complementary nucleotides and connects them through the formation of phosphodiester bonds. The other strand is referred to as the coding strand and will have an identical sequence to the newly synthesised RNA, except for the presence of thymine instead of uracil. Eventually RNA polymerase will reach a codon which does not code for an amino acid but tells the enzyme to stop transcribing (these are called stop codons). A molecule of messenger RNA (mRNA) has been formed which will leave the nucleus and enter the cytoplasm.
Once in the cytoplasm, the messenger RNA finds its way to structures called ribosomes, which are basically protein-building machines. The ribosome attaches itself to the RNA and slides along it. The ribosome ‘reads’ the mRNA in a series of three bases (such as AUG, CCA, GCU) called codons. Each codon corresponds to a particular amino acid. As the ribosome reads the codons, a transfer RNA (tRNA) molecule which has a complementary anticodon carries an amino acid to the ribosome. Once the ribosome has read through the length of the mRNA, a series of different amino acids will have been dropped off by several tRNA molecules. Peptide bonds form between the amino acids to form a protein.
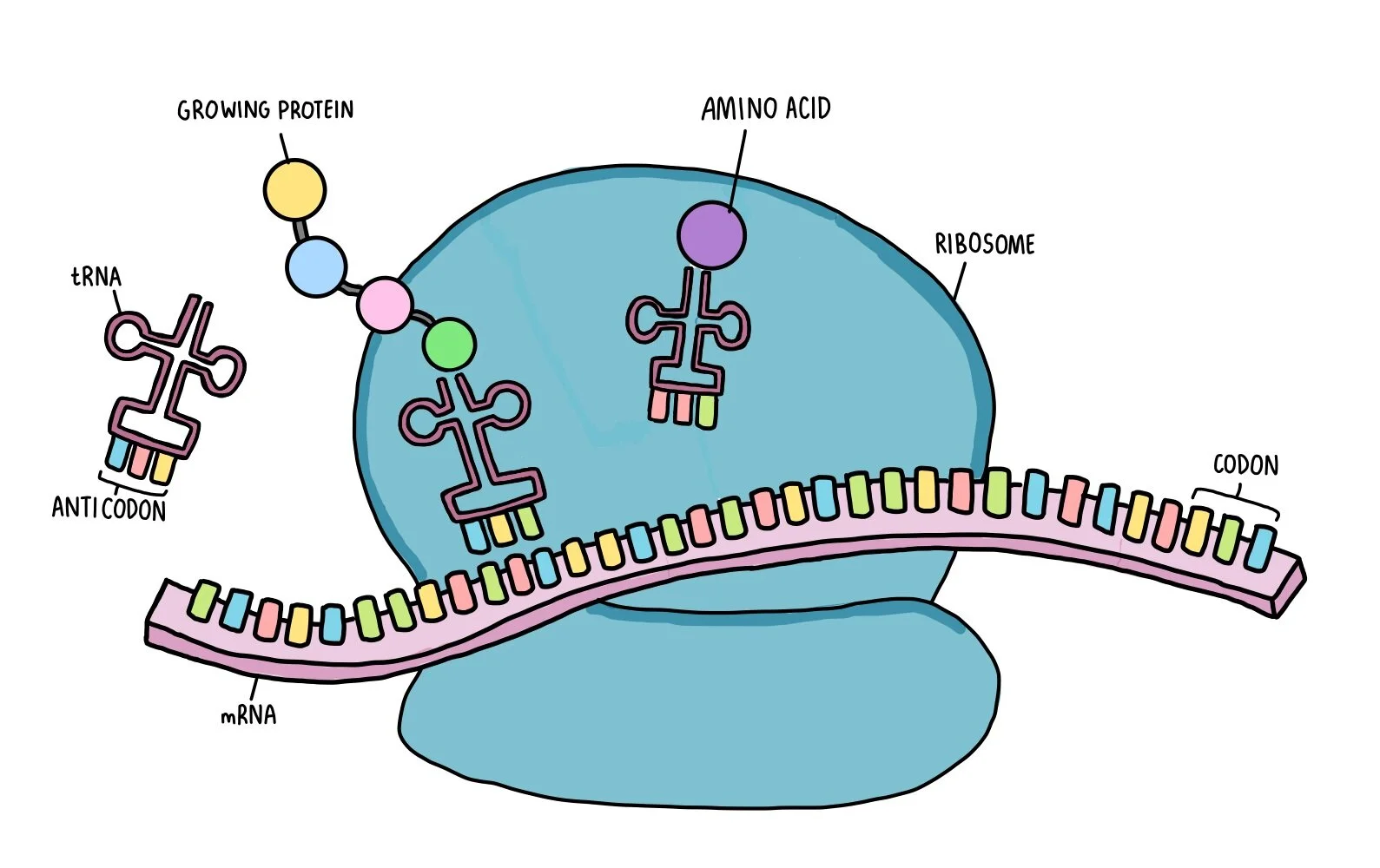
tRNA molecules have an usual clover-shaped structure, formed by a single RNA strand folded over on itself through hydrogen bonding. At one end of the molecule, there is an amino-acid binding site and at the other there is an anticodon, which contains a complementary base sequence to the mRNA codon.
The Nature of the Genetic Code
The genetic code can be described in a number of ways - it is a triplet code, non-overlapping, degenerate and universal.
Triplet code: three nucleotide bases make up a codon, which code for a particular amino acid.
Non-overlapping code: the codons do not overlap. Once the ribosome has ‘read’ one codon and the appropriate amino acid has been recruited, the ribosome moves onto a new codon.
Degenerate code: different codons can code for the same amino acid. For example, the codons CUU and CUC both code for the amino acid leucine. This means that some mutations will have no effect on the organism since the same protein will still be produced.
Universal code: all organisms use the same genetic code. Bacteria, bonobos and bananas all contain DNA made up of the four nitrogenous bases that are found in humans.
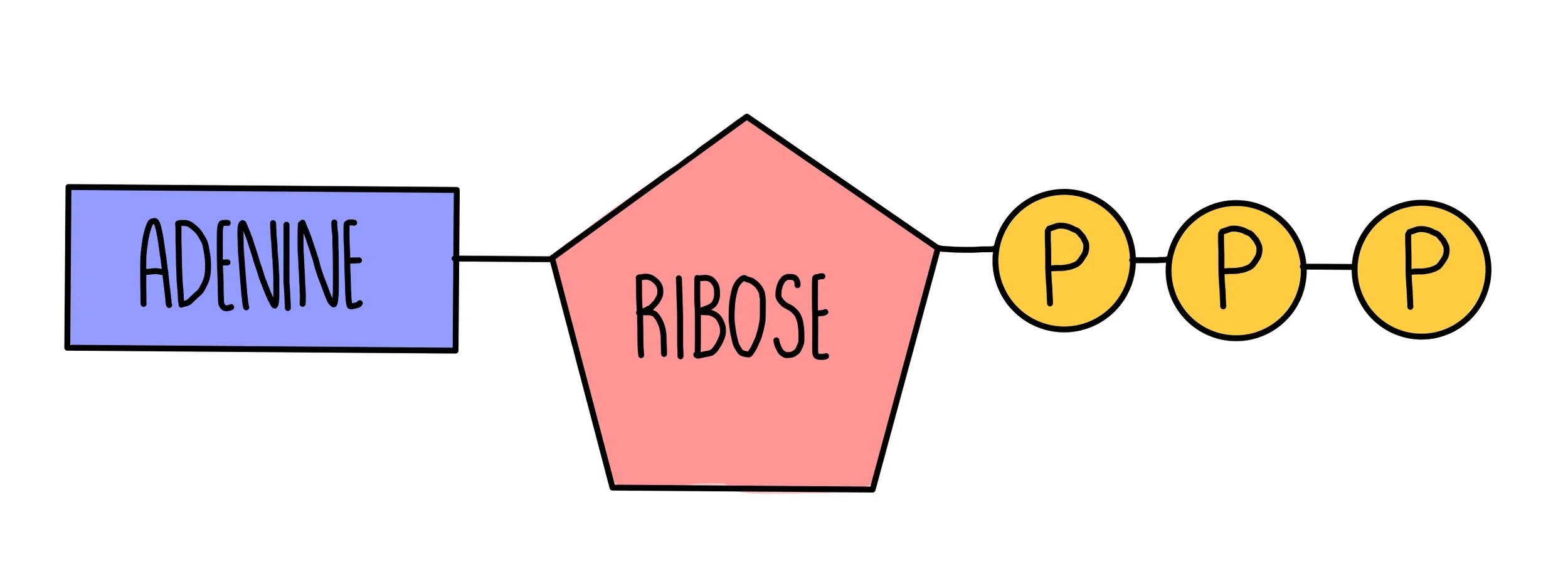
Adenine triphosphate (ATP)
ATP is a phosphorylated nucleotide. It’s structure consists of a ribose sugar and adenine attached to three phosphate groups. Hydrolysis of ATP to ADP removes one of the phosphate groups and releases energy in a single reaction.
Did you know..
Around 8% of the DNA in your genome isn’t actually human but comes from viruses. When viruses infect a host organism, they insert their DNA into the host’s DNA so that the host organism starts transcribing and translating viral proteins. These proteins assemble into a virus, bursting out of the cell and can spread to other organisms, for example, through lipid droplets when we sneeze.
Next Page: Enzymes